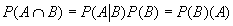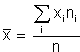Aquí se dio acabo la segunda prueba del primer parcial

Docente a cargo Ing. Mónica Mantilla de la Escuela Politécnica Nacional

El objetivo de este blog es crear un ambiente en el que se pueda transmitir conocimientos de Probabilidad y Estadística.

En un mundo globalizado compartir información es de vital importancia el aprendizaje.

Vacía tu bolsillo en tu mente, y tu mente llenará tu bolsillo.

Abre tus brazos al cambio, pero no dejes ir tus valores.